Web pages are created for humans as end-users, but there is a lot of useful data in the form of text in the backend of a website.
Web scraping is a process of extracting and harvesting large amounts of data from the websites in a matter of minutes (depending on the research request and data availability), and compilling that data into a spreadsheet for further enriching and processing.
With the help of different software and tools, our team of researchers can extract all the information that might be valuable and of interest to both you and your business. We can crawl, fetch and extract data from any website on the web and deliver results in a spreadsheet or upload them directly to your CRM.
Who can benefit from this playbook?
The website scraping playbook is a great way to get leads for every department. With the list of leads generated with this playbook, your sales and marketing teams will always be busy.
Once you get the results of the scrape compiled in a spreadsheet or uploaded to your CRM, there are a couple of ways you could use the leads:
Create audiences for Google AdWords and Facebook Ads and run paid campaigns
What data we deliver
Scraping Data from Web Pages
Data Extraction for Analysis
Harvesting Images, PDF, Contacts, etc.
Product Reviews and Keyword Scraping
Scrape Text from Website
Real State Data Extraction
Data Extraction from Blogs, Websites
What you should know before starting Web scraping?
There are two ways that you can scrape website information:
Using code and coding skills
Using existing tools
If you have some coding skills under your belt, here is what you need to know before you start scraping:
Understand what is the robots.txt file
Have knowledge of different programming languages (Python. Ruby, etc.)
Know how the pages are created
However, if you are not familiar with coding, or you simply don’t have time to create your own process, you can try some of the existing scraping tools:
We decided to go with the simplest tool there is, and since we have been using it for a long time, we know it’s reliable.
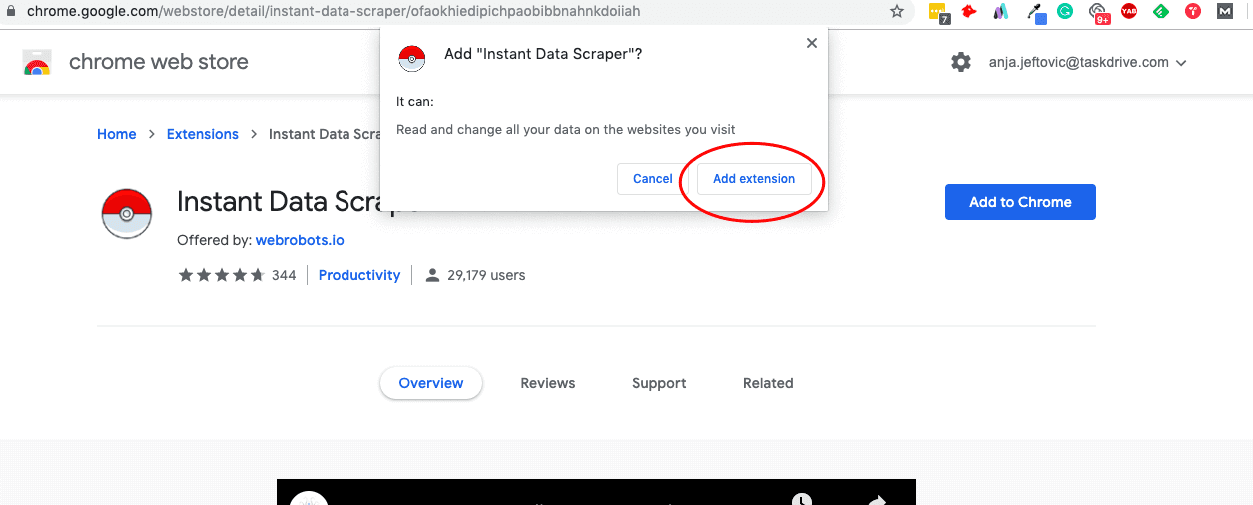
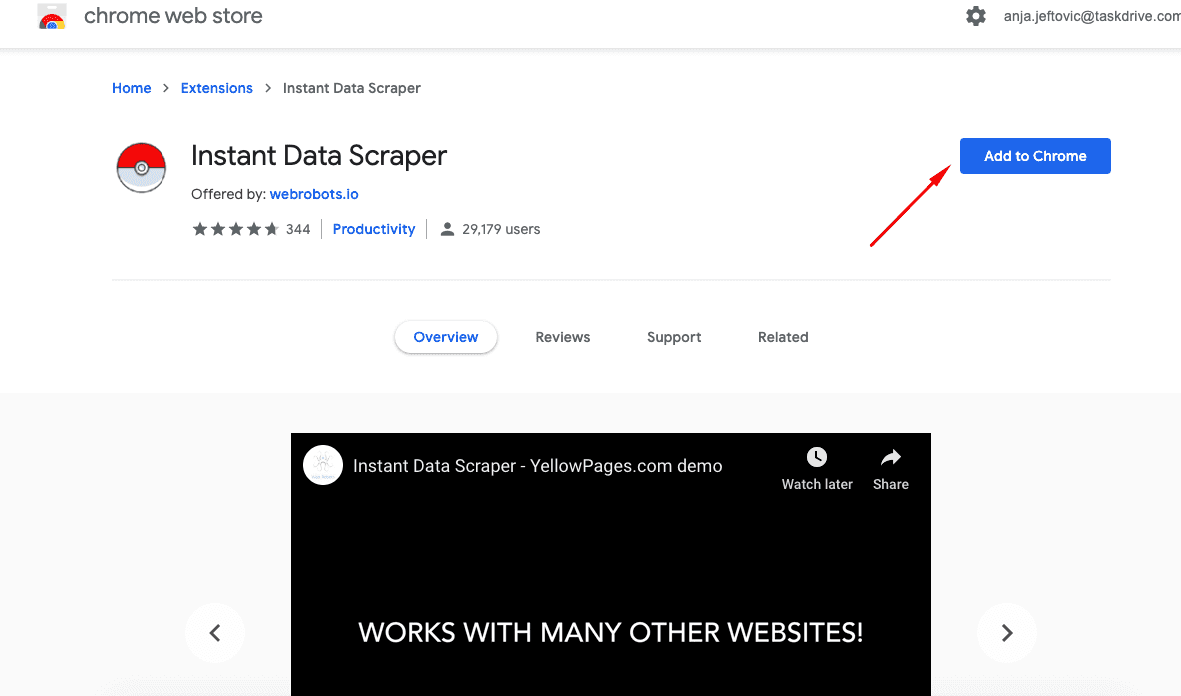
Go to the Google Chrome Web Store and install Instant Data Scraper. It’s a free Chrome add-on that recognizes information on the website and can download it into a spreadsheet.
Step 1
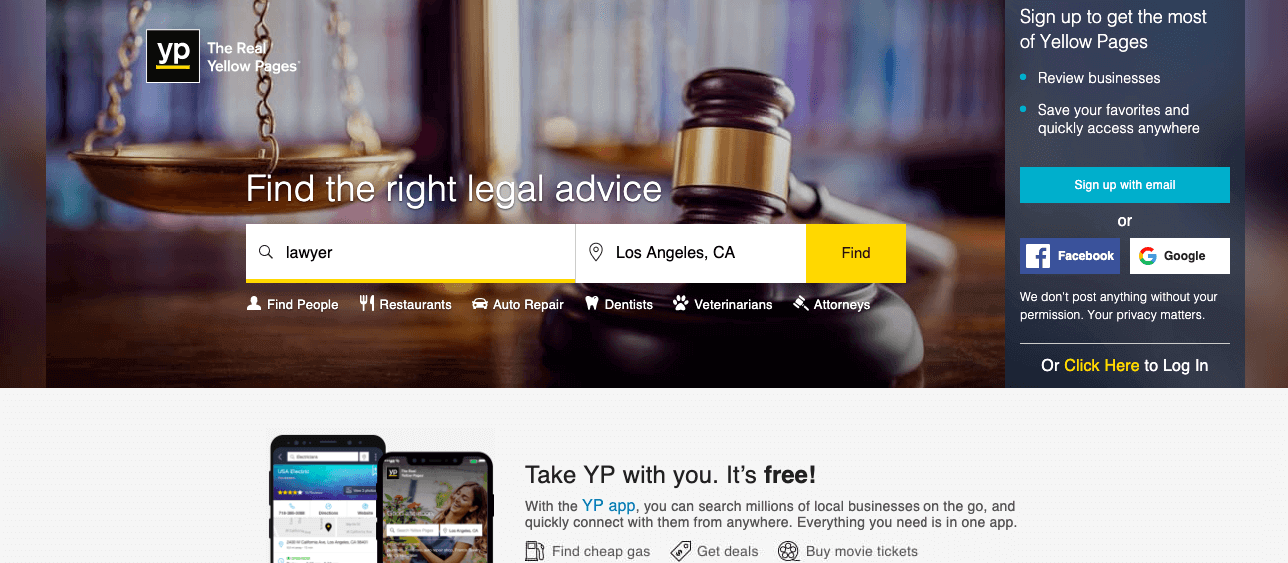
Define your research requirements. Let’s say you are looking for a list of lawyers in Los Angeles.
Find a website that lists the information you need, for example, Yellow Pages.
Type in your search query in the search box:
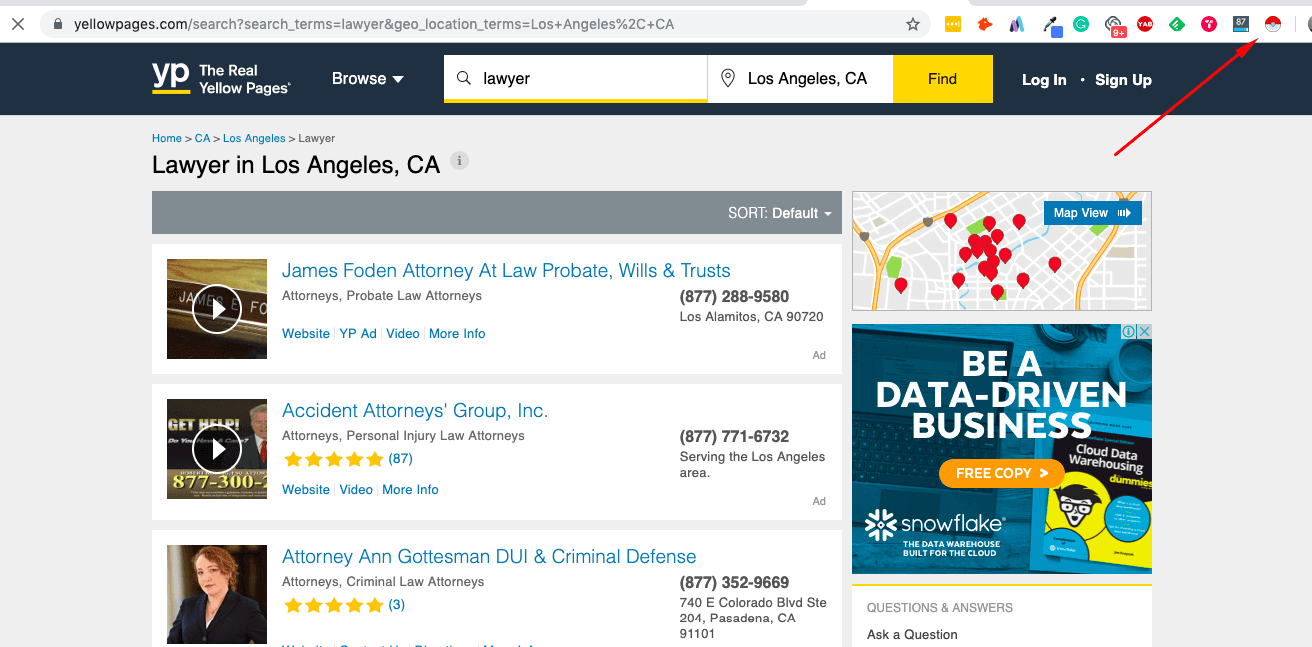
Step 2
Once you have the search results ready, use the Instant Data Scraper plug-in to scrape the information. This is how you do it:
a. Click on the Pokeball icon at the top right corner of your browser:
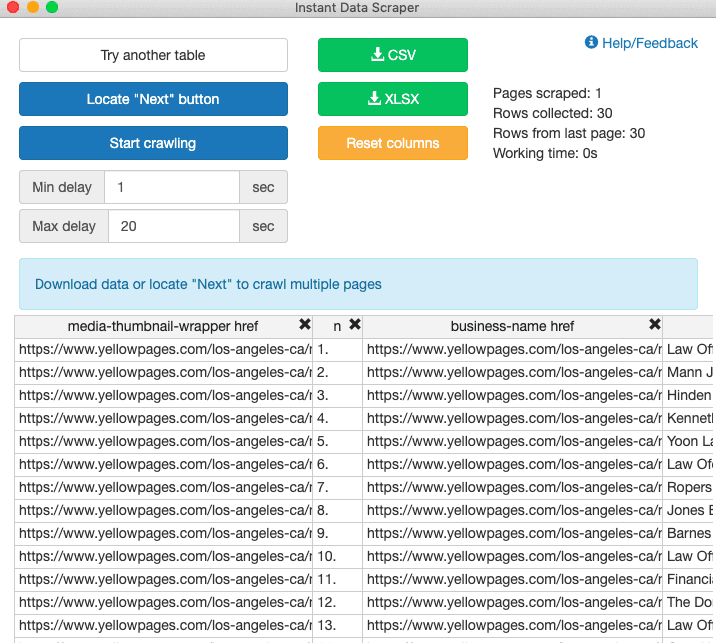
b. The tool will scrape the page and offer you a preview of the results:
You can choose which columns you want to keep or delete and click Start crawling. If the results are shown on multiple pages, click on the Locate “Next” Button so the tool can scrape all the other pages as well.
Step 3
Once the scrape is done, you can download the file in .CSV or .XLSX file form.
Step by step in a video:
Step 4
Upload the downloaded file to your Google Drive and open it in Google Sheets where you can edit the spreadsheet further (e.g. removing unnecessary columns).
Step 5
Use filters, to filter out the information that is not important or you don’t want to use it right now.
For example, you’re looking only for General Practice Attorneys:
Use filter “text contains” for the column “Category”
Type in “General Practice Attorneys”
Voila, you will see all the results
Step 6
Check if there’s any other list cleaning required, leave only the data you need > less is more
Step 7
The final step is to enrich the data with the information you need – email addresses, phone numbers, LinkedIn profiles… Whatever you think is necessary for your list of leads. This also depends on the goal you are looking to achieve.
At TaskDrive, we use different tools that enable us to extract almost any information from websites. Aside from Instant Data Scraper, we also use the Phantombuster API integration with Google Spreadsheets.
Feel free to test out this tutorial and let us know how it goes.
If you are short on time or people that will do the research, don’t hesitate to contact TaskDrive. We’d be happy to put our Web Scraping Playbook to work and also enrich the data for you.